
The cut Linux command is a useful tool to extract the desired data from a delimited format file or output like csv, xml or json.
Normally, depending on the type of file, it needs some preprocessing before gathering successfully the data from them by combining it with other commands like awk, sed or tr.
By using the cut command, it is possible to get the information needed from logs for further troubleshooting or auditing, for transforming the file’s format or be part of a bash script to automate any task.
Extract data with delimiter and field options
Let’s say that we have the following file that we want to process:

Then, considering the character “,” as a delimiter of the values, we want to obtain the third one for each line. The expected result should be:
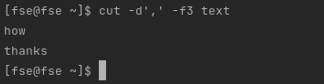
- “how”
- “thanks”
Therefore, the cut command to be executed is:
$ cut -d',' -f3 text The -d or –delimiter option tells cut to consider a predefined character as a separator of values, while the -f or –fields option tells cut to obtain the value from a particular position number.
The result of executing the above cut command in the example text file is:
But that was for extracting a single value from the file. What if you want to obtain multiple values using the same delimiter? Fortunately, the cut -f option provides some flexibility and admits a list of position numbers separated by “,” or ranges by using the “-” character. Let’s see some examples:
Obtaining the values 1, 3 and 5 from the example text file:
$ cut -d',' -f3,5,1 text
Getting values from position 4 to 6:
$ cut -d',' -f4-6 text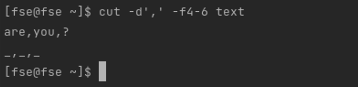
Which is equivalent to the following execution without specifying the last position:
$ cut -d',' -f4- text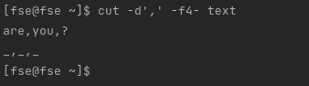
You may combine both approaches to obtain a more complex output that fits your desired outcome:
$ cut -d',' -f1,4-6 text
Let’s see other cut use cases with different files or outputs. In the following command, combining cut commands will get the minutes and seconds from date:
$ date | cut -d' ' -f4 | cut -d':' -f2,3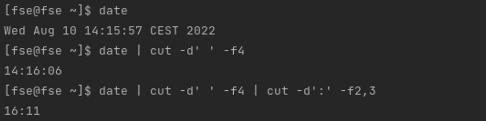
Another use case that would be interesting to know how to process it, is the files or outputs that the fields are separated by a variable number of spaces. In this example, we want to get the space available and the mount path from the df -h command. To do so, we first adapt the output with sed command to then extract the data with cut:
$ df -h | sed 's/ */ /g' | cut -d' ' -f4,6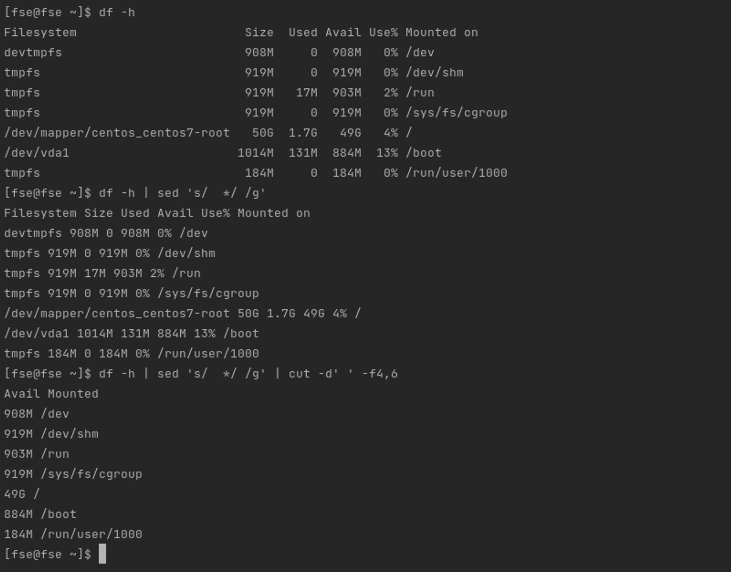
Finally, another particular use case that you might encounter is when you want to get the list of class file names from a jar package, but not the full paths. It might sound simple but the hassle here is that the class files could be at different levels of nested folders.
For this example, we have unpackaged part of the well known spring package jar file:
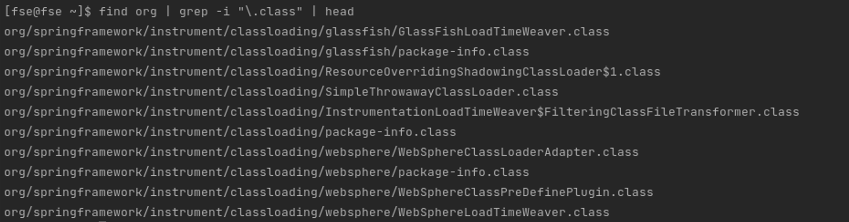
The command used above is composed of the find command to list recursively the “org” folder files, the grep is to get only the java class files and head to get a sample of the output. The sample shows that class files are at different nested folder levels.
If we go straightforward with the previous output with the cut command, then it would be complex to get those class files in the “classloading” folder, and also in the “glassfish” folder in a single execution.
However, to overcome case, it is possible to keep things simple by using the rev command. This one reverses the order of the line characters, thus, placing the filename of the class at the first position if we process the output with cut.
Therefore, the whole command would look like:
$ find org | grep -i "\.class" | rev | cut -d'/' -f1 | rev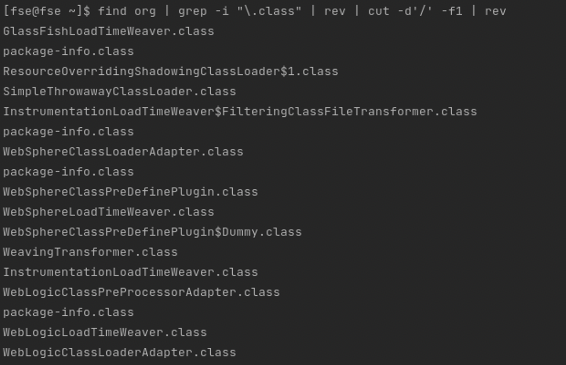
There you go. The list of classes file names from the org folder. Note that the second rev command is to revert back the original character order.
Get the data from a character position number
Another way to run cut command is by character position number without the need of defining any delimiter.
$ cut -c2-7 text